Mama mia! Drive failure! 🚨 How to replace faulty drive in CEPH storage ?
It might seem daunting... it’s stressful... and it feels urgent... but you'll be surprised at how easy it is with Proxmox + Ceph.


Houston, we have a problem! One of my drives in the Ceph pool just bit the dust!
I need to swap it out asap, but how does that work with Ceph storage?
No worries—let’s dive into it in this article.
How can I see that one of my drives has failed ?
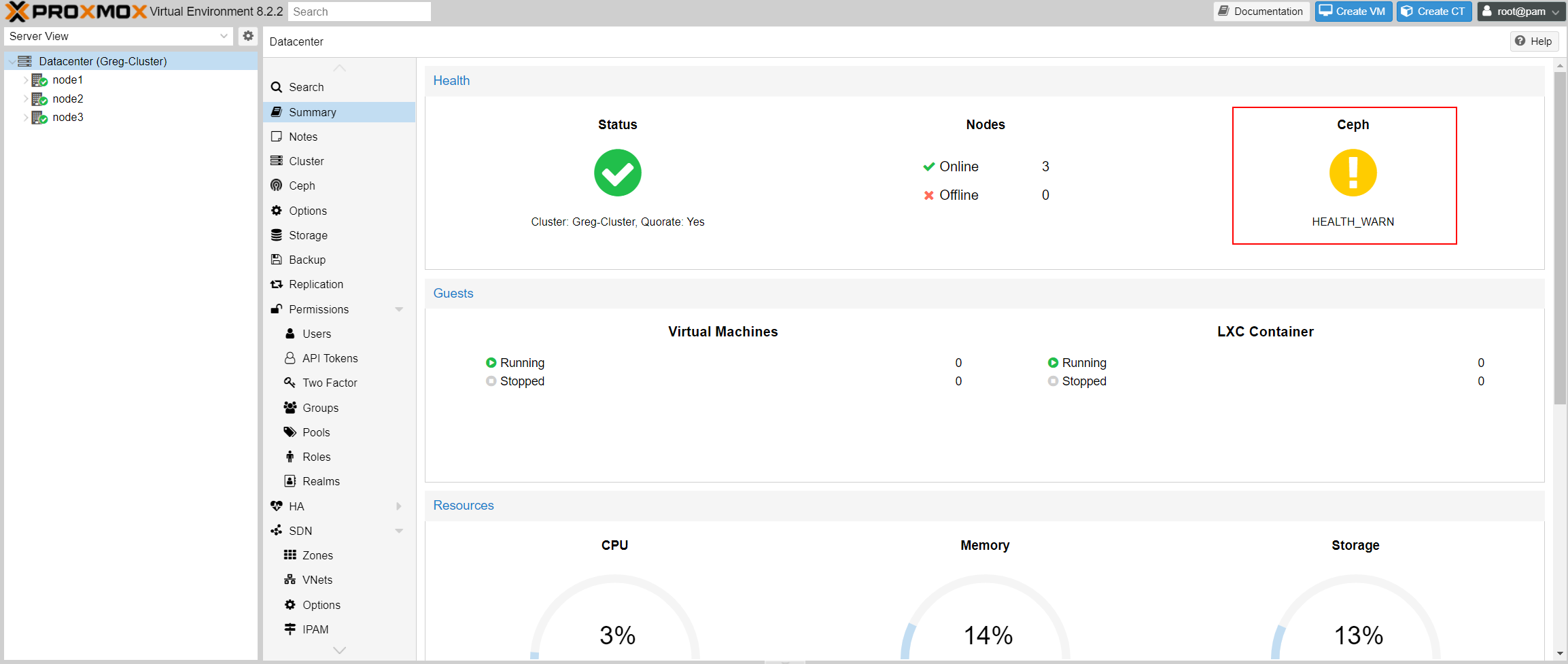
First, on the Proxmox summary screen, the CEPH cluster will show as unhealthy:
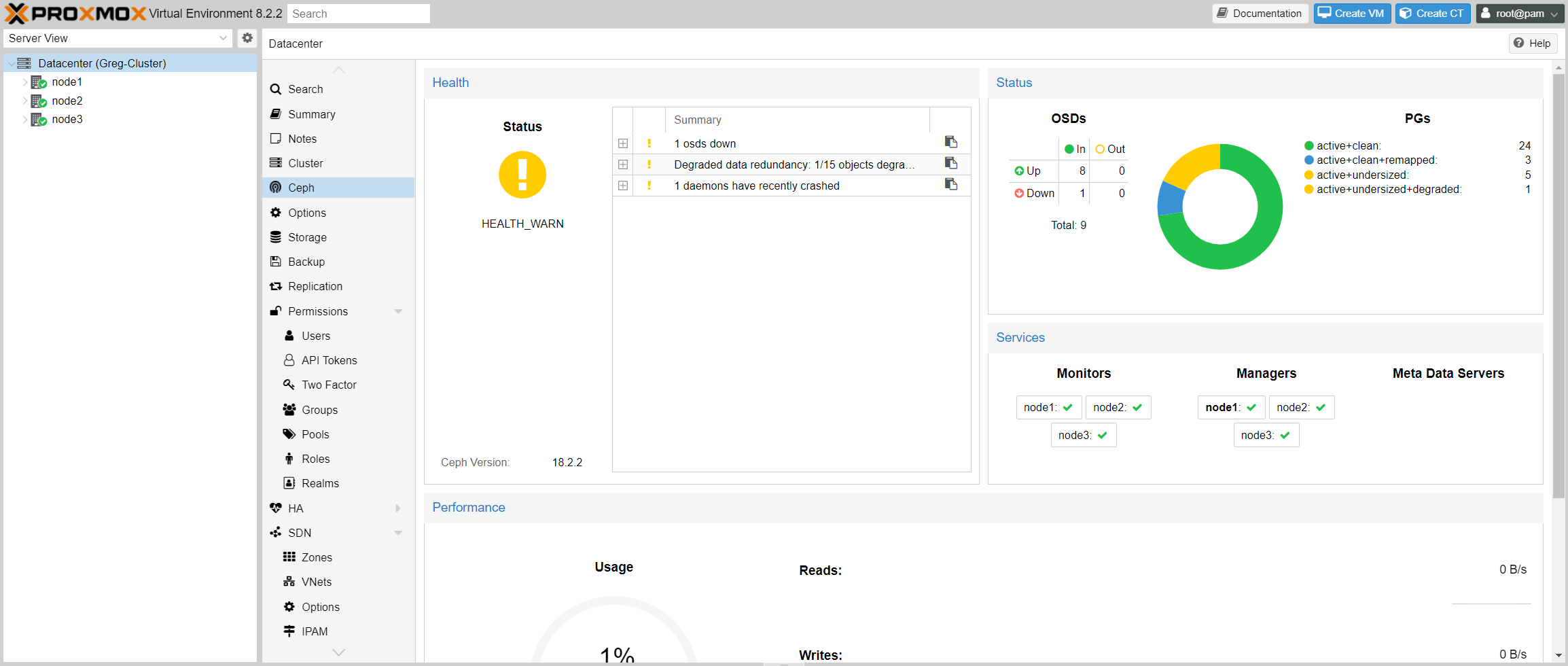
The CEPH dashboard will also indicate that the CEPH cluster is experiencing some issues:
How do you identify the faulty drive?
Go to one of your Proxmox node, then to CEPH -> OSD:
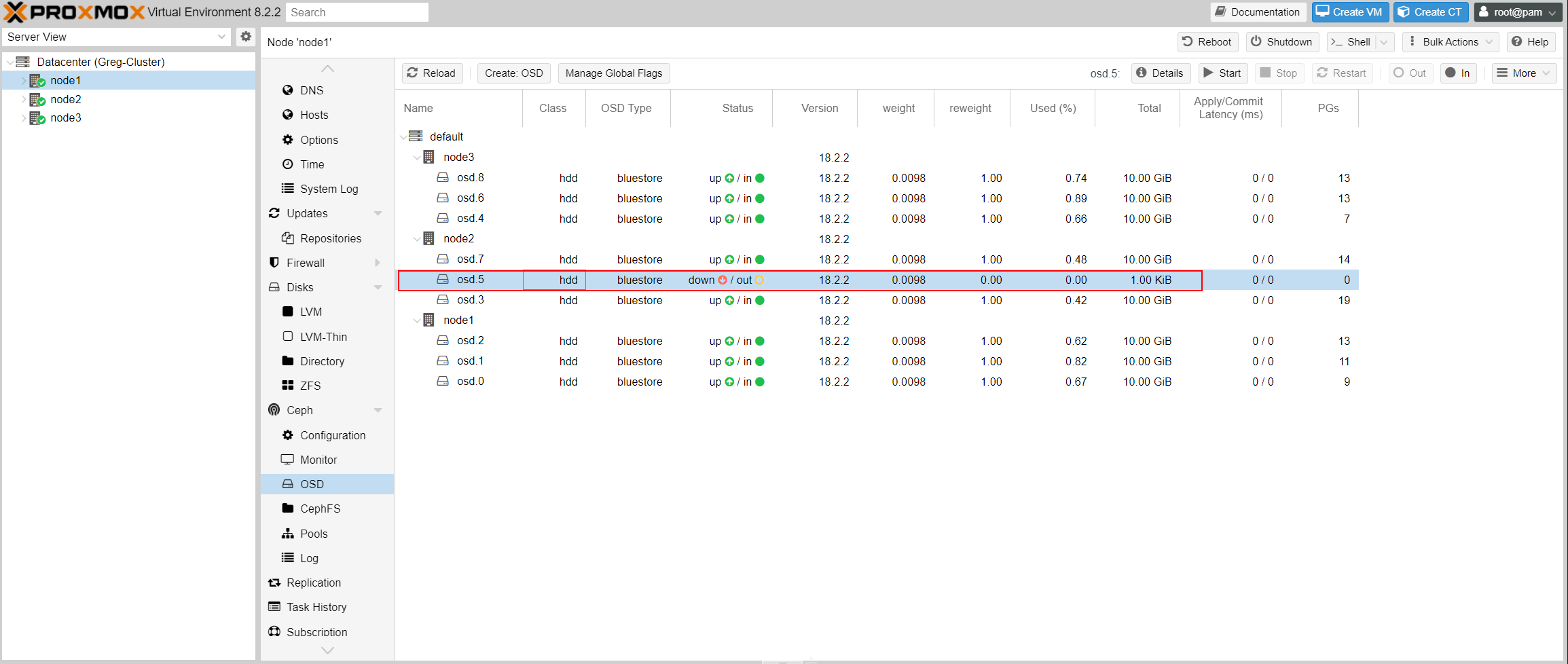
The OSD will show which disk is down and automatically remove it from the cluster.
If that doesn’t happen, you’ll need to manually remove the drive from the OSD before taking any further action.
-> To do this, select the OSD and click the "Out" button.
How to remove the faulty drive ?
Next step is to select the faulty drive and to destroy it from the OSD:
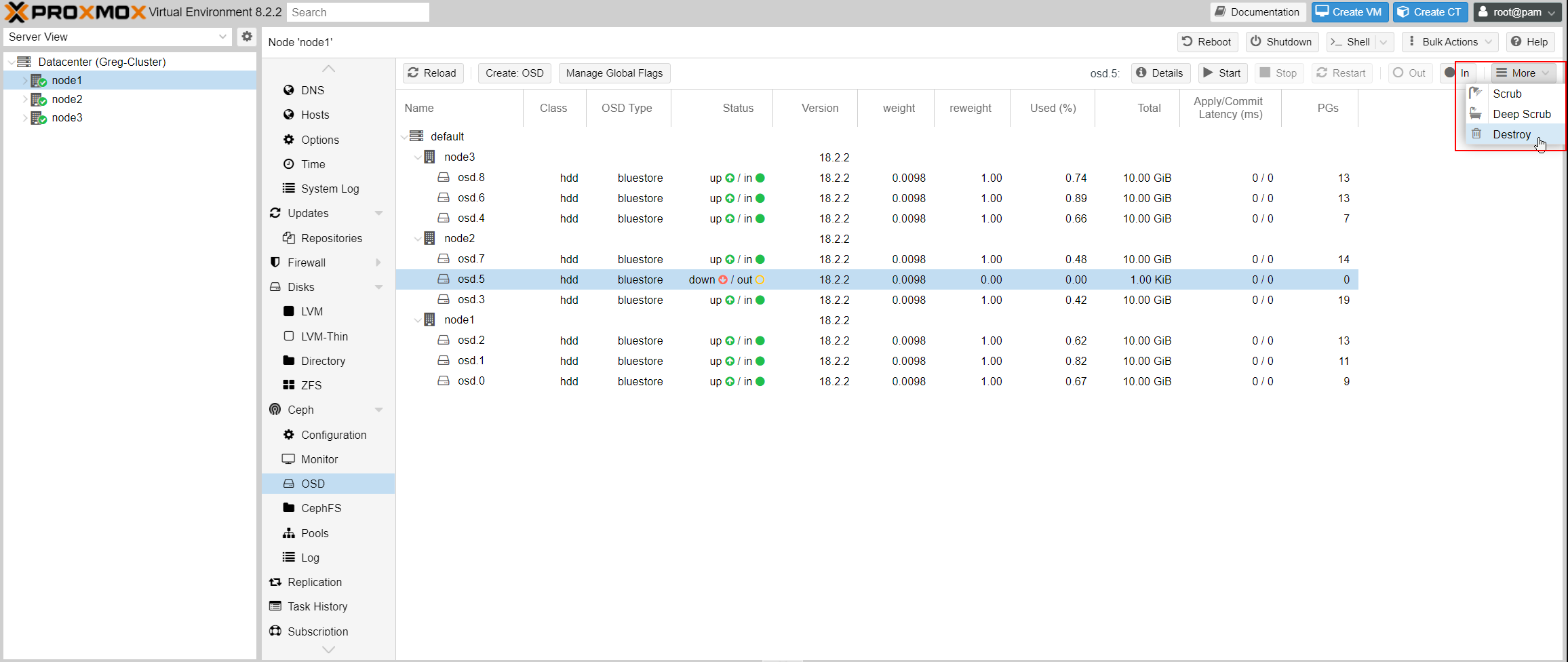
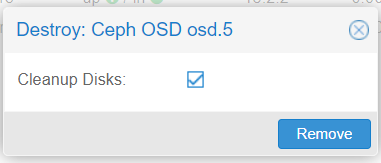
If the disks on this server aren’t hot-swappable, you can turn off the server. The disk is now no longer part of the cluster, so you can safely remove it from the node2 server and replace it with a new one.
Select node2 -> ceph -> OSD and click on "Create OSD":
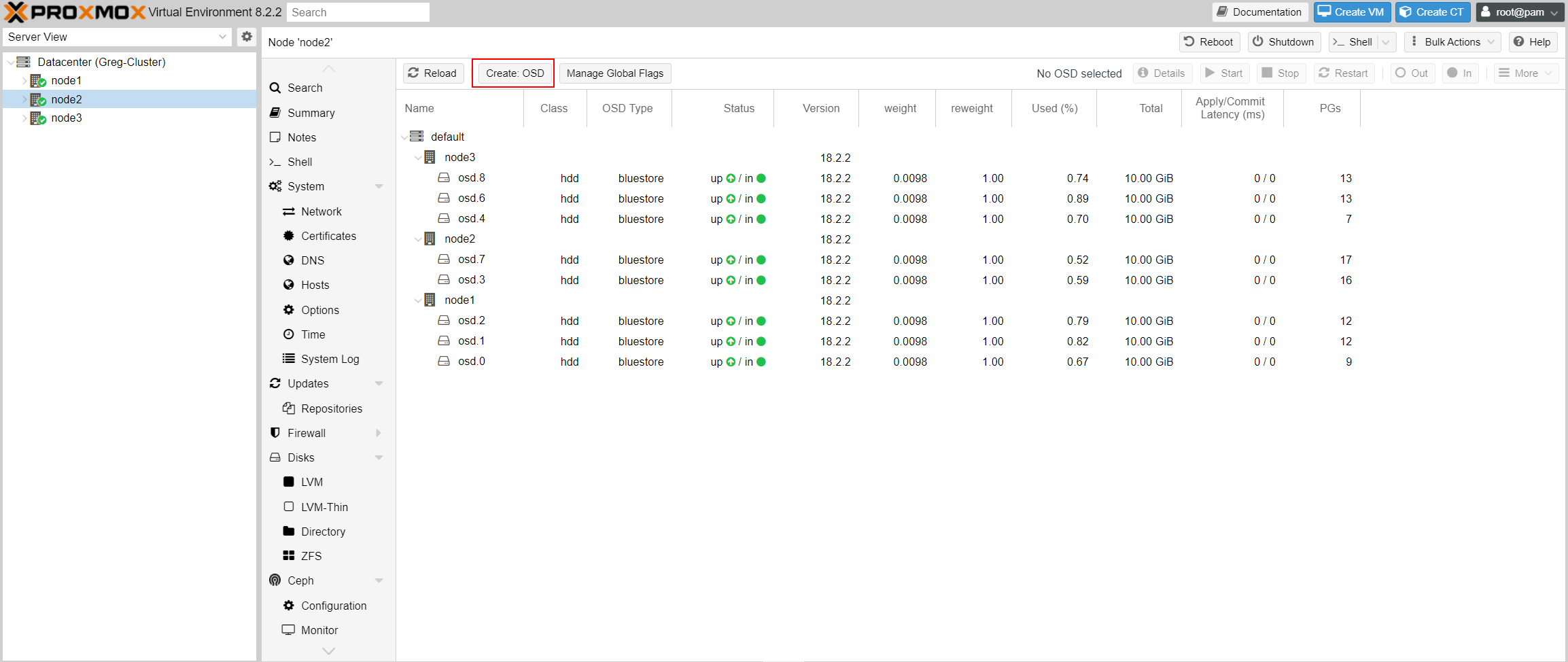
Select the new disk added and hit "create":
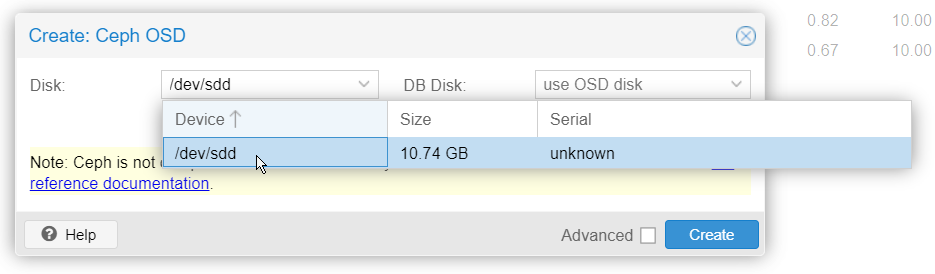
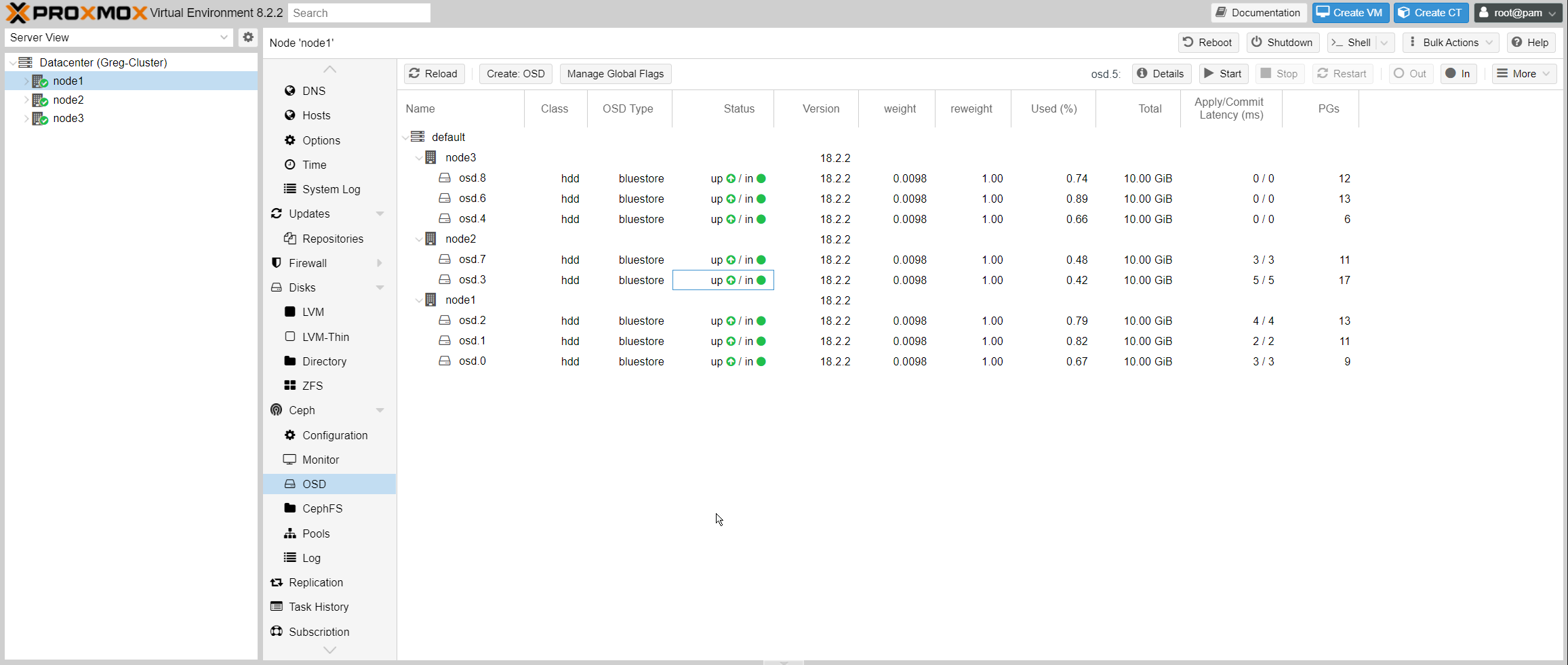
The disk will now appear online and up in the cluster:
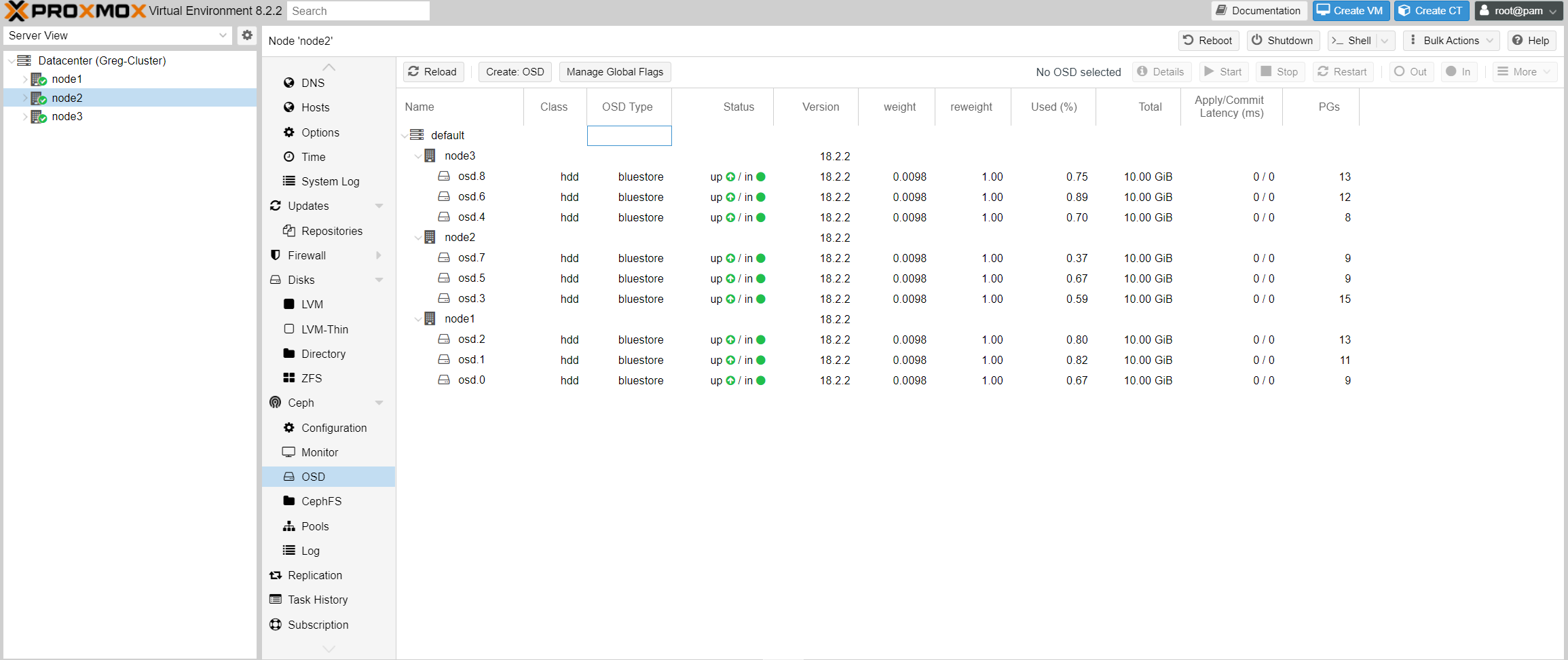
In the background, Ceph will automatically start rebalancing the blocks between the existing OSDs and the newly added one.
Et voilà! That’s all there is to it—just follow the simple steps above.
It’s a breeze!
And since CEPH uses erasure coding or simple replication method instead of RAID, you won’t be stuck waiting on some never-ending rebuild based on disk size.
This is Ceph in zen mode! 🧘♂️✨

Additionally, it’s possible that the Ceph daemon might crash when a disk fails.
You’ll see an alert pop up on the Ceph dashboard if that happens:
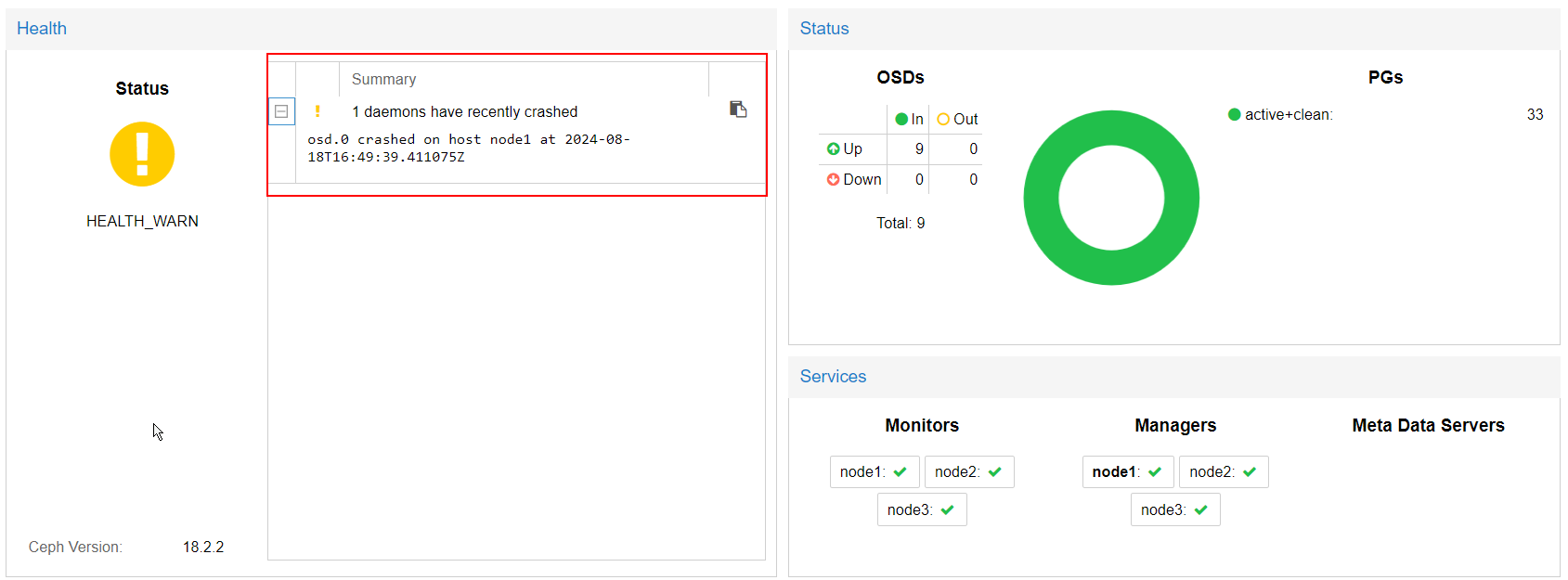
To acknowledge this alert, go to the node's shell and enter the following command:
ceph crash lsas a return, you will see the list of ongoing alert with their UID:

Copy the UID into the following command to acknowledge the alert:
ceph crash archive 2024-08-18T16:49:39.411075Z_5b5fb5d4-c674-4ced-88ee-d7e73127daa0And just like that, your Ceph dashboard is back to its happy, healthy self! 😌